PaperReview
Introduction
Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding
Binarized Neural Networks
Trained Ternary Quantization
DSD
INCREMENTAL NETWORK QUANTIZATION
Distilling the Knowledge in a Neural Network
Learning bothWeights and Connections for Efficient Neural Networks
BinaryConnect
Googlenet
SqueezeNet
vgg
Deep Residual Learning
Powered by
GitBook
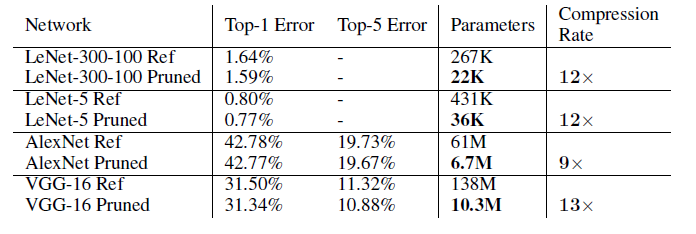
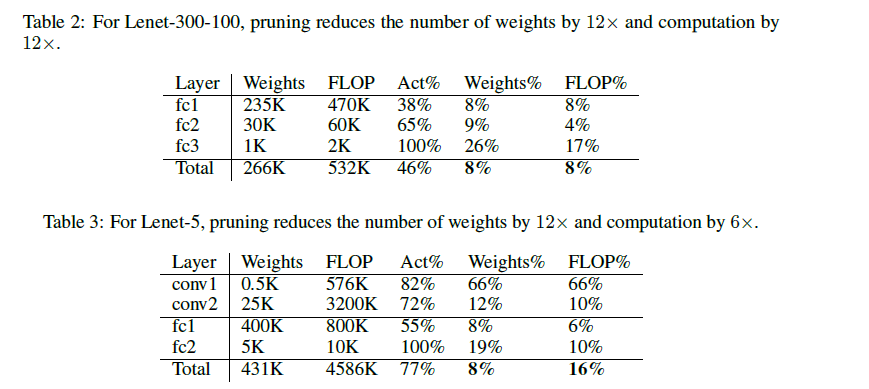
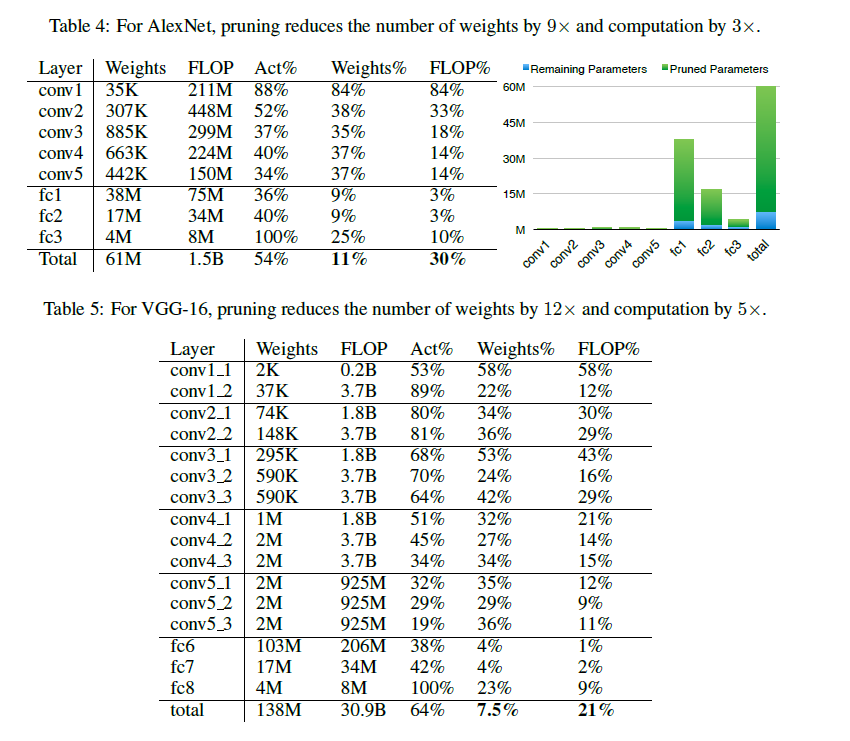
Learning bothWeights and Connections for Efficient Neural Networks
Learning both Weights and Connections for Efficient
Neural Networks
https://arxiv.org/abs/1506.02626
https://github.com/garion9013/impl-pruning-TF
results matching "
"
No results matching "
"